McKinsey says agentic AI can change the economics of insurance core modernization. The missing question is how carriers prove the agents are right before risk, audit, and regulators sign off.
AI in insurance earns trust when the carrier can prove what the system did, why it did it, who approved it, and whether the result matches the policy, claim, billing, or underwriting behavior the business depends on. Trust is not a model claim. It is evidence: rule provenance, data lineage, test coverage, human approval, and regulator-readable audit trail.
Insurance is an unusually good test of enterprise AI trust because the workflows are old, consequential, and heavily documented in systems that were never designed to explain themselves. A policy-administration migration is not just a code migration. It is embedded business rules, actuarial settings, batch windows, custom interfaces, product exceptions, billing states, claims behavior, and operational judgment accumulated over decades.
That is why the current agentic AI conversation matters. Agents may finally make the work economically viable. But the question that determines whether a carrier can rely on the work is not "can the agent move fast?" It is "can the carrier prove the agent is right?"
McKinsey changed the demand side of the conversation.
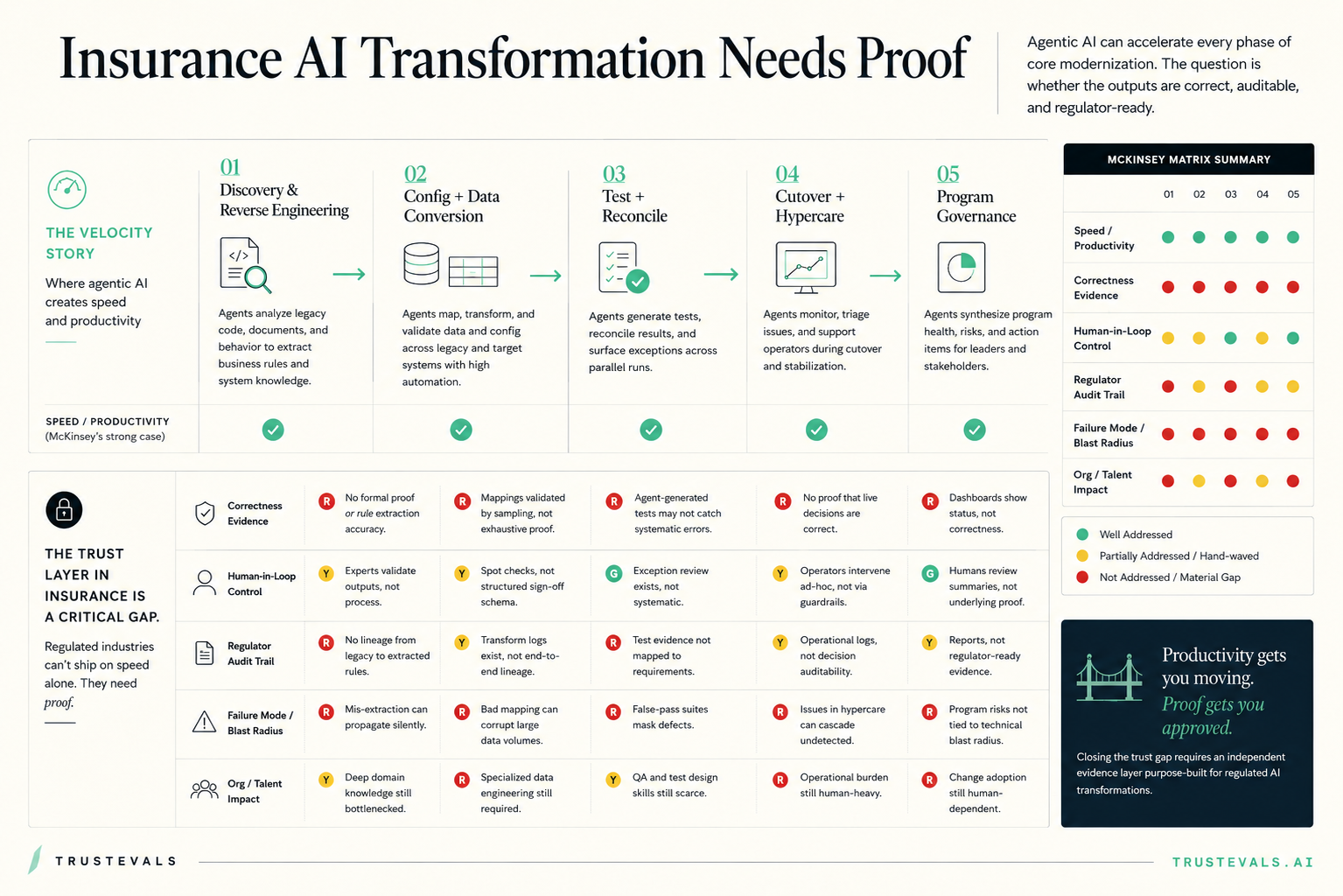
McKinsey's April 2026 article argues that agentic AI can reshape insurance core modernization by compressing discovery, mapping, testing, reconciliation, cutover, and governance loops. The piece is persuasive on speed. It is much thinner on correctness evidence, regulator audit trail, failure-mode containment, and independent proof.
That gap is the TrustEvals wedge. A consulting firm can model productivity. A systems integrator can configure the target platform. The carrier still needs an independent evidence layer that tells the CIO, CRO, internal audit, and state DOI whether the agent-assisted migration is safe to rely on.
The proof matrix for AI in insurance.
The useful way to read the McKinsey thesis: agents can accelerate five lanes of modernization, and each lane needs proof before the program can be trusted.
G = the public thesis addresses the dimension credibly. Y = it gestures at the issue but does not define the artifact. R = the proof burden is still largely unbuilt.
The pattern is simple. Speed is the green row. Correctness, regulator evidence, and blast-radius containment are the red rows. That is the difference between an impressive modernization deck and a migration the carrier can defend.
Modernization can accelerate migration. Trust comes from proof that survives the room.
Agent-assisted programs can move the work faster than the old migration cadence.
The defensible artifact is independent evidence, not the agent's own story.
What the evidence pack has to prove.
A trusted insurance AI program needs artifacts that survive outside the implementation room. The output cannot be "the agent said so." It has to be inspectable by risk, compliance, internal audit, the board, and eventually a regulator.
Where did this business rule come from, which legacy branch or policy artifact produced it, and who approved it as canonical?
How did each source field move into the target platform, what transformations occurred, and which exceptions remain open?
What test set was built from production behavior, SME judgment, incident history, and financial materiality rather than the same agent output?
Which policies, claims, premiums, reserves, or billing states reconcile against the legacy system, and which differences are approved?
Who signed off on extracted rules, mappings, cutover criteria, defects, rollback decisions, and material exceptions?
What stops a false-green test suite, silent data loss, wrong premium calculation, or bad cutover recommendation from spreading?
The independent oracle is the load-bearing piece. If an agent extracts a rule incorrectly and then generates the test from the same extracted rule, the test can pass while the migrated behavior is wrong. Trust starts when the test source is independent of the agent path being tested.
Where TrustEvals fits in the modernization program.
TrustEvals should not be positioned as the system integrator. The SI owns delivery. TrustEvals owns the evidence layer under delivery: the questions, tests, traces, gates, and audit artifacts that prove whether the agent-assisted work is safe to rely on.
Evaluate extracted business rules against source artifacts, SME review, and production examples. Produce provenance, confidence, and approval status per rule.
Evaluate semantic mapping, conversion completeness, exception handling, rounding behavior, and source-to-target lineage across Guidewire, Duck Creek, Sapiens, EIS, or internal target platforms.
Build independent golden sets and differential tests. Separate generated test coverage from proof that migrated behavior matches legacy behavior where it matters.
Turn cutover criteria, parallel-run findings, rollback decisions, and exception approvals into a decision log the carrier can inspect after the bridge closes.
Roll traces, defects, owner status, material exceptions, and remediation progress into a board-readable audit memorandum instead of a false-green PMO report.
A practical 90-day plan.
Trust in insurance AI does not require the carrier to solve every migration problem on day one. It requires the proof system to be in place before agent outputs become program truth.
Name the modernization lanes, AI agents, source systems, target systems, human approvers, regulatory exposure, and material business outcomes.
Create golden sets and replay cases from production behavior, SME review, historical defects, high-value policies, claim edge cases, and financial thresholds.
Publish the first evidence pack: pass/fail results, open exceptions, owner map, approval log, control gaps, and the decision criteria for moving to the next migration wave.
This is intentionally smaller than a full modernization program. The first job is to make the proof layer real. Once the evidence system exists, every migration wave becomes easier to evaluate and harder to fake.
The channel partner motion.
Systems integrators running Guidewire, Duck Creek, Sapiens, EIS, or custom core-modernization programs are the natural partners. They own implementation and change delivery. TrustEvals gives them a credible independent evidence layer they cannot self-mark without conflict.
Target-platform design, configuration, data conversion, integration, cutover execution, training, and program delivery.
Evaluation design, proof matrix, independent tests, control gates, trace evidence, audit memorandum, and risk-readable program status.
The carrier gets a cleaner operating model. Delivery keeps moving. Risk is not asked to trust the builder's self-grade. The board gets an evidence pack instead of another modernization status deck.
Sources behind this guide.
This guide uses public insurance and AI-governance source material as the outside anchor. It does not claim a named insurance customer or confidential engagement result.
McKinsey, "Can agentic AI (finally) modernize core technologies in insurance?"
NAIC Model Bulletin: Use of Artificial Intelligence Systems by Insurers
Keep the operating read connected.
AI in insurance trust questions, answered plainly.
Insurers build trust in AI by proving the system's outputs against the business process it affects: rule provenance, data lineage, differential testing against legacy behavior, human approval gates, monitoring thresholds, and audit-ready evidence that risk, compliance, and regulators can inspect.
The biggest risk is a false sense of correctness. If an agent reads a legacy rule incorrectly and then generates tests from the same misunderstanding, the program can produce a clean-looking test suite that misses the actual production behavior.
A carrier should require rule provenance, source-to-target data lineage, reconciliation logs, representative golden test sets, defect-to-financial-impact mapping, rollback criteria, human approval records, and a regulator-readable audit memorandum.
The implementation partner owns delivery of the target platform. TrustEvals owns the independent proof layer: evaluation design, trace evidence, control gates, audit artifacts, and the operating view that shows whether the agent-assisted work is safe to rely on.
No. The same evidence layer applies to claims, billing, underwriting, broker workflows, fraud detection, customer-facing AI, and adjacent legacy utilities. Policy administration is the sharpest starting point because the cutover risk is visible to the board.
The fastest insurance AI program still has to prove the system can be trusted.
Bring one workflow, vendor, or AI portfolio. We will map the evidence needed for finance leaders to fund, ship, or stop it.
Related links and sources
Start Trust thesis
/marketing/resources/insurance-ai-transformation-needs-proof.png
- GUIDE Trust, mapped for finance.AI AUDIT AI Trust for Finance.
{kind=link}